
Topological Invariance and Breakdown in Learning
Authors
Yongyi Yang, Tomaso Poggio, Isaac Chuang, Liu Ziyin
Abstract
We prove that for a broad class of permutation-equivariant learning rules (including SGD, Adam, and others), the training process induces a bi-Lipschitz mapping between neurons and strongly constrains the topology of the neuron distribution during training. This result reveals a qualitative difference between small and large learning rates $η$. With a learning rate below a topological critical point $η^*$, the training is constrained to preserve all topological structure of the neurons. In contrast, above $η^*$, the learning process allows for topological simplification, making the neuron manifold progressively coarser and thereby reducing the model's expressivity. Viewed in combination with the recent discovery of the edge of stability phenomenon, the learning dynamics of neuron networks under gradient descent can be divided into two phases: first they undergo smooth optimization under topological constraints, and then enter a second phase where they learn through drastic topological simplifications. A key feature of our theory is that it is independent of specific architectures or loss functions, enabling the universal application of topological methods to the study of deep learning.
Concepts
The Big Picture
Imagine you’re sculpting a lump of clay. Your hands stretch, bend, and reshape it without tearing. Holes stay holes, bumps stay bumps, and the clay remains one connected piece. Push too hard, though, and it tears, merges, or collapses into something simpler. The shape you started with is gone.
Neural networks work the same way. Every time you train a deep learning model, you’re choosing, often unknowingly, whether your network undergoes a gentle reshaping or a violent structural collapse.
The difference comes down to a single number: the learning rate, which controls how large a step the training algorithm takes when adjusting the network’s weights. Researchers have tuned this setting by trial and error for decades, guided by intuition and empirical rules. A team at MIT, the University of Michigan, and NTT Research has now found a mathematical reason why it matters so much.
Their paper, “Topological Invariance and Breakdown in Learning”, proves the existence of a topological critical point, a precise threshold η* that separates two completely different modes of training behavior. Below it, the shape of your neural network’s neuron distribution is protected by mathematics. Above it, all bets are off.
Key Insight: Every permutation-equivariant optimizer, including SGD and Adam, either preserves the topology of the neuron distribution exactly or destroys it. The learning rate alone determines which regime you’re in.
How It Works
Start with a feature so obvious it’s easy to miss: permutation symmetry. In a standard neural network layer, swapping two neurons (trading the i-th row of one weight matrix with the j-th) produces exactly the same function. The neurons are interchangeable labels, not fixed identities.
Standard optimizers respect this symmetry, so they treat neurons equivariantly: swap the labels, and the updates swap with them. The researchers show this constraint forces each training step to induce a bi-Lipschitz mapping, a transformation that neither stretches nor compresses distances too aggressively. Nearby neurons stay nearby; distant neurons stay distant. This is exactly what topologists call a homeomorphism: a structure-preserving map.
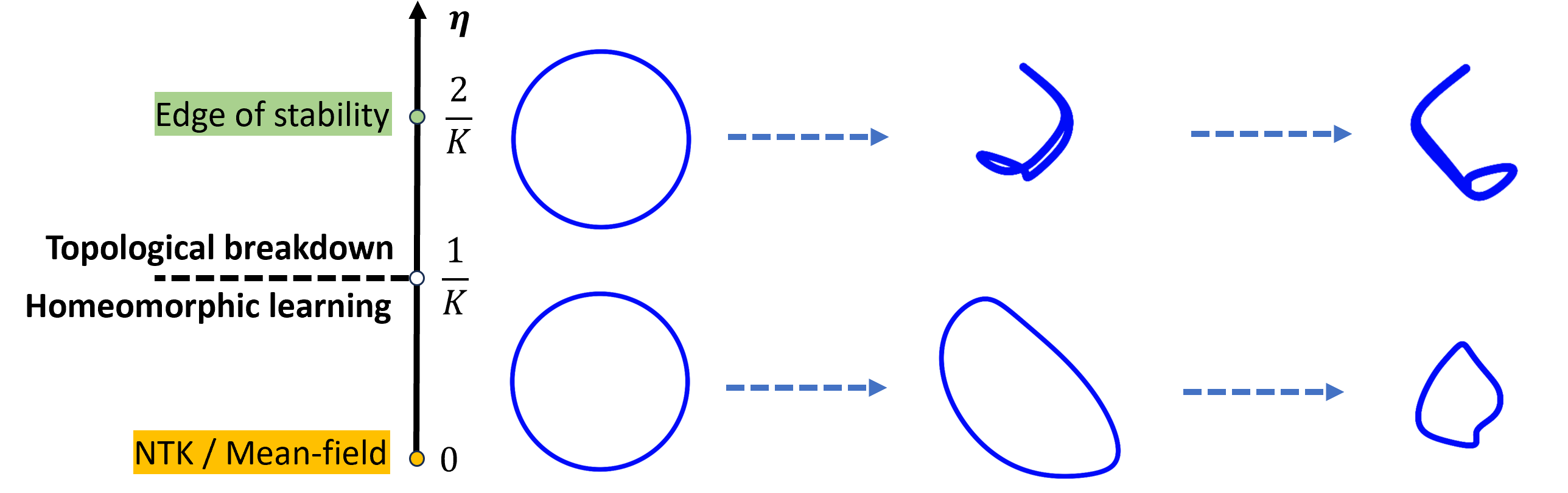
The protection only holds below η*, which the researchers derive from the local geometry of the loss landscape.
Above η*, the bi-Lipschitz guarantee breaks down. The mapping from one step to the next degrades from a homeomorphism to a continuous surjection, a map that can collapse distinct neurons into a single point. Once neurons merge, information is irreversibly lost. The network’s structure becomes coarser, simpler, lower-dimensional.
This gives a clean two-phase picture of gradient descent:
- Phase 1 (small η, topology preserved): The network evolves smoothly within topological constraints. Neurons explore the loss landscape without changing the fundamental shape of their distribution.
- Phase 2 (large η, topological breakdown): The network crosses the edge of stability. Neurons merge, redundant structure collapses, and expressive capacity decreases.
The two-phase picture connects directly to the recently discovered edge of stability, the tendency for gradient descent to drift toward learning rates where updates destabilize training. The topological framework gives that phenomenon a new interpretation: the edge of stability is where the network tips from topology-preserving to topology-breaking dynamics.
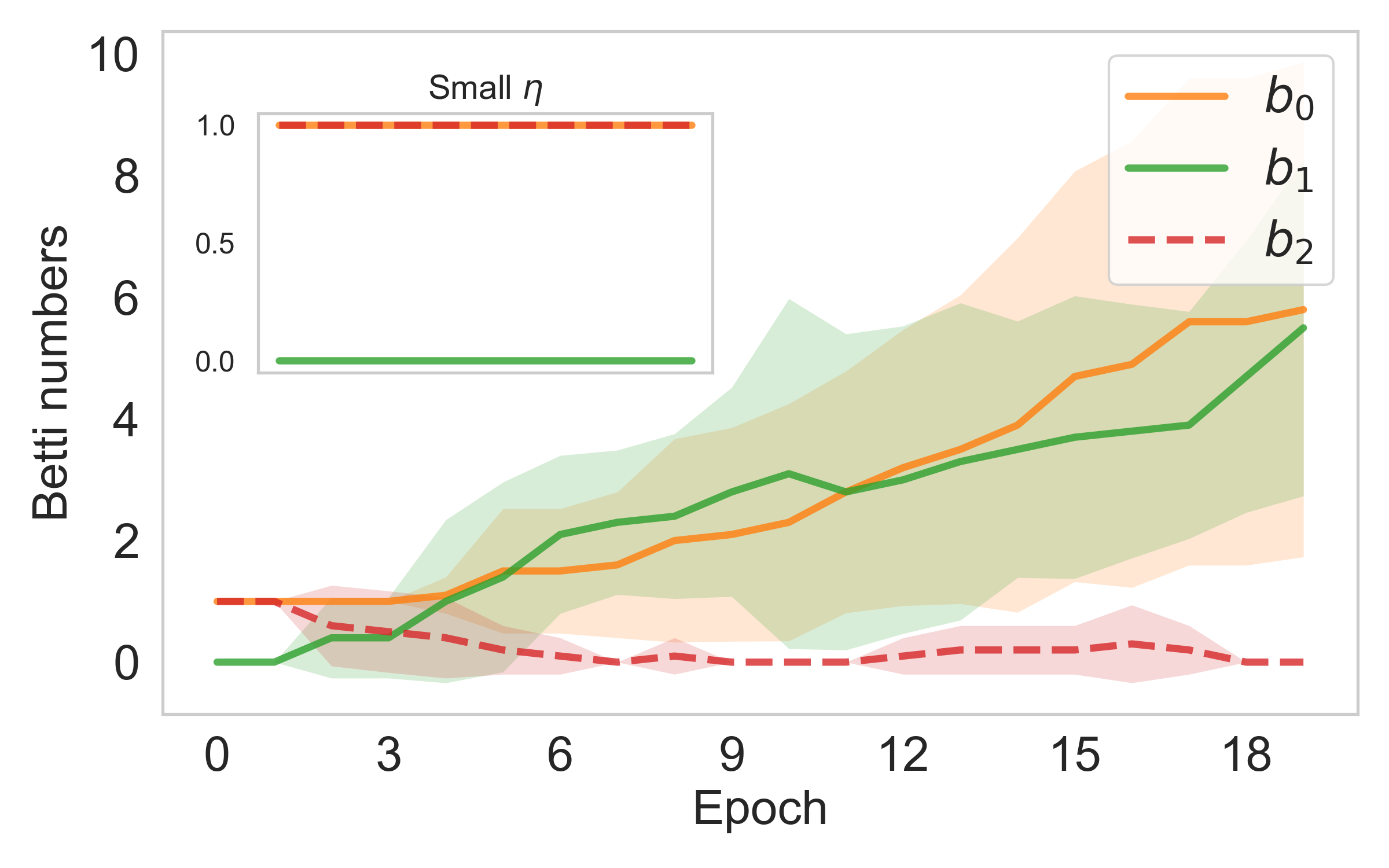
The result holds across architectures. Convolutional layers, fully connected layers, self-attention in transformers: all share the same permutation symmetry structure. No assumptions about the loss function are needed either. This is a property of learning itself, not of any particular model.
Why It Matters
Learning rate schedules (warmup, cosine decay, step drops) are among the most carefully tuned settings in modern deep learning, yet they’ve been developed almost entirely by trial and error. This theory offers a principled basis for those choices.
Large learning rates early in training can actively simplify the model topology, acting as an implicit regularizer. Small learning rates late in training preserve whatever structure the network has found. The familiar “large then small” schedule most practitioners use may be exploiting this topological mechanism without knowing it.
There’s also a plausible connection to neural collapse, the phenomenon where late-stage training causes a network’s internal representations to lose richness and distinctiveness. If topological breakdown drives this capacity loss, monitoring proximity to η* could flag the problem early. Future work might develop diagnostics that track topological complexity in real time, or design optimizers that deliberately control which phase they operate in.
The bridge to physics runs deeper than analogy. In condensed matter physics, phenomena like topological insulators are characterized by topological invariants: numbers that capture a material’s fundamental structure and change only at sharp transitions called critical points. The authors note this connection explicitly. Tools from topological field theory could transfer directly to the study of neural networks. The threshold η* is, in this framing, a genuine phase transition, not metaphorically, but mathematically.
Bottom Line: Training a neural network isn’t just optimization. It’s a topological process with a sharp phase boundary. Cross η*, and your network enters a regime where topology collapses and capacity shrinks. Stay below it, and the geometry of your model is mathematically protected.
IAIFI Research Highlights
This work imports the mathematical language of topology, a cornerstone of modern physics, into the theory of deep learning. The result is a rigorous phase transition framework that mirrors topological phenomena in condensed matter physics.
The paper provides the first architecture-independent, optimizer-independent proof of a topological critical point in training dynamics. It offers a theoretical foundation for learning rate schedule design and a new lens on implicit regularization.
By formalizing the connection between permutation symmetry and topological phase transitions, this work opens a path for applying physics concepts, including topological field theory, to the study of computation and learning.
Future directions include topological diagnostics for training health and exploring topological complexity as a measure of generalization. See [arXiv:2510.02670](https://arxiv.org/abs/2510.02670) for the full paper by Yang, Poggio, Chuang, and Ziyin.