
Training a Foundation Model for Materials on a Budget
Authors
Teddy Koker, Mit Kotak, Tess Smidt
Abstract
Foundation models for materials modeling are advancing quickly, but their training remains expensive, often placing state-of-the-art methods out of reach for many research groups. We introduce Nequix, a compact E(3)-equivariant potential that pairs a simplified NequIP design with modern training practices, including equivariant root-mean-square layer normalization and the Muon optimizer, to retain accuracy while substantially reducing compute requirements. Nequix has 700K parameters and was trained in 100 A100 GPU-hours. On the Matbench-Discovery and MDR Phonon benchmarks, Nequix ranks third overall while requiring a 20 times lower training cost than most other methods, and it delivers two orders of magnitude faster inference speed than the current top-ranked model. We release model weights and fully reproducible codebase at https://github.com/atomicarchitects/nequix.
Concepts
The Big Picture
Imagine trying to predict the properties of every possible material in the universe: how it conducts heat, whether it stays stable under pressure, how atoms vibrate within its crystal lattice. For decades, physicists relied on quantum mechanical calculations so computationally expensive that simulating a single material could take days on a supercomputer cluster. AI models that learn to predict how atoms interact (called interatomic potentials) promised to change that, making accurate predictions thousands of times faster. But training these AI models has become a competition for computing resources that only the biggest labs can afford to enter.
The latest generation of “foundation models” for materials can cost tens of thousands of GPU-hours to train. That shuts out most university research groups, national labs on tight budgets, and scientists in less-resourced parts of the world. The assumption has been that better performance requires more compute. A team at MIT decided to challenge that directly.
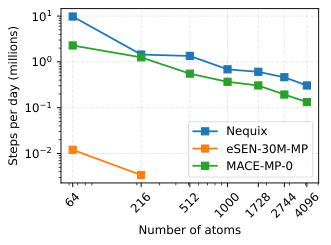
Researchers Teddy Koker, Mit Kotak, and Tess Smidt built Nequix: a compact AI model for predicting materials properties that achieves near-state-of-the-art accuracy at a fraction of the cost. It ranks third on major community benchmarks while requiring 20 times less compute than most competitors and running 100 times faster at inference.
Key Insight: By pairing a compact neural network architecture with optimization tricks borrowed from the machine learning speedrunning community, Nequix shows that efficiency and accuracy don’t have to be in tension. Frontier materials science AI doesn’t require a supercomputer budget.
How It Works
Nequix is built on E(3)-equivariant neural networks: networks with a mathematical guarantee that their predictions don’t change when you rotate or reflect the input atomic structure. A crystal of iron has the same energy whether you orient it north-south or east-west, so the network needs to respect that symmetry. The team designed Nequix as a leaner version of NequIP, an established equivariant architecture, stripping away complexity while preserving the physics that matters.
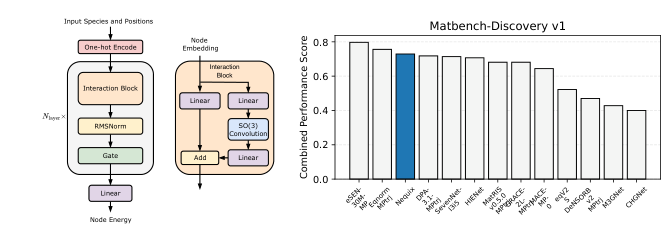
The architectural changes are targeted. Two simplifications from recent literature reduced parameter count without sacrificing expressiveness: replacing species-specific self-connection layers with a single linear layer, and discarding unused non-scalar representations from the final layer. The team also added equivariant RMSNorm, a stabilizing technique that normalizes the network’s internal signals, adapted to handle the directional quantities (vectors and tensors) that physics-aware networks must track. This stabilizes training and plays well with the new optimizer they chose.
The optimizer choice proved just as important. Instead of the standard Adam optimizer used in virtually every deep learning workflow, the team adopted Muon, a recently proposed optimizer from researchers who compete to train neural networks on benchmarks as fast as possible. Muon uses an algorithm from numerical linear algebra to ensure each weight update points in a unique direction, encouraging different neurons to learn genuinely distinct features. In practice, Nequix reaches equivalent accuracy to Adam-trained models in just 60-70% of the training epochs, with a 7% reduction in energy prediction error.
The efficiency gains stack across the full pipeline:
- Dynamic batching fills each GPU batch to memory capacity rather than using fixed-size batches, keeping hardware utilization high even when atomic structures vary wildly in size
- Custom CUDA kernels (low-level GPU programs written specifically for Nequix) fuse the expensive equivariant tensor product operation with message-passing into a single step, eliminating costly intermediate memory allocations
- 100 training epochs on MPtrj (a database of ~1.5 million quantum chemistry calculations), completed on just two A100 GPUs in 50 hours, for 100 GPU-hours total
The final model has 700,000 parameters. Large language models routinely exceed 70 billion. Nequix is tiny, and that’s the point.
Why It Matters
The Matbench-Discovery benchmark is the field’s most demanding test for materials AI: it asks models to screen 257,000 candidate crystal structures for thermodynamic stability, predicting which will survive synthesis and which will fall apart. Nequix ranks third among compliant models (those trained only on MPtrj for a fair comparison). It also ranks third on the MDR Phonon benchmark, which tests predictions of lattice vibrations relevant to thermal conductivity.
Third place while spending one-twentieth the compute budget is not a consolation prize. It’s a different kind of result entirely.
The field has been climbing a scaling curve: well-funded institutions train ever-larger models on ever-larger datasets, with the implicit message that a massive compute budget is the price of admission to frontier research. Nequix suggests there’s a parallel path, one focused on architectural efficiency, smarter optimization, and broader access. When a model can be trained for the cost of a few hundred dollars in cloud compute, a graduate student at a small university can reproduce and build on frontier work. That changes the sociology of the field, not just the benchmarks.
Open questions remain. Nequix was trained on MPtrj, a dataset dominated by inorganic crystalline solids; how well the approach generalizes to molecules, surfaces, or disordered materials is unresolved. The Muon optimizer is new enough that its behavior across different problem domains isn’t fully characterized. The reproducible codebase and released model weights mean the community can start answering these questions now.
Bottom Line: A 700K-parameter model trained in 100 GPU-hours can compete with the best materials AI on the planet. That opens up foundation model-quality predictions to researchers who can’t afford the usual compute bill, and it challenges the assumption that better materials science just requires bigger computers.
IAIFI Research Highlights
Interdisciplinary Research Achievement: Nequix brings together modern deep learning optimization techniques, including the Muon optimizer from the ML speedrunning community, with the geometric symmetry constraints of physical chemistry. The result is a model that is both computationally lean and physically principled.
Impact on Artificial Intelligence: Equivariant RMSNorm combined with the Muon optimizer significantly speeds up convergence in physics-constrained neural networks, offering a training recipe that could benefit equivariant models across scientific domains beyond materials.
Impact on Fundamental Interactions: By making accurate interatomic potential prediction accessible at low computational cost, Nequix lowers the barrier for ab initio-quality materials screening, speeding up the discovery of stable new materials relevant to energy storage, superconductivity, and quantum technologies.
Outlook and References: Future directions include extending Nequix-style efficiency to larger and more diverse training datasets and applying these optimization strategies to other equivariant architectures. The model and code are available at github.com/atomicarchitects/nequix (arXiv:2508.16067).