
Two Watts is All You Need: Enabling In-Detector Real-Time Machine Learning for Neutrino Telescopes Via Edge Computing
Authors
Miaochen Jin, Yushi Hu, Carlos A. Argüelles
Abstract
The use of machine learning techniques has significantly increased the physics discovery potential of neutrino telescopes. In the upcoming years, we are expecting upgrade of currently existing detectors and new telescopes with novel experimental hardware, yielding more statistics as well as more complicated data signals. This calls out for an upgrade on the software side needed to handle this more complex data in a more efficient way. Specifically, we seek low power and fast software methods to achieve real-time signal processing, where current machine learning methods are too expensive to be deployed in the resource-constrained regions where these experiments are located. We present the first attempt at and a proof-of-concept for enabling machine learning methods to be deployed in-detector for water/ice neutrino telescopes via quantization and deployment on Google Edge Tensor Processing Units (TPUs). We design a recursive neural network with a residual convolutional embedding, and adapt a quantization process to deploy the algorithm on a Google Edge TPU. This algorithm can achieve similar reconstruction accuracy compared with traditional GPU-based machine learning solutions while requiring the same amount of power compared with CPU-based regression solutions, combining the high accuracy and low power advantages and enabling real-time in-detector machine learning in even the most power-restricted environments.
Concepts
The Big Picture
Imagine trying to run a hospital’s MRI machine on a car battery, buried under a mile of Antarctic ice. That’s roughly the engineering challenge facing scientists who want to use machine learning at neutrino telescopes. These enormous instruments, some spanning cubic kilometers of ocean water or polar ice, sit in places where power is precious, bandwidth is limited, and the physics is extraordinary.
Neutrino telescopes like IceCube in Antarctica, and the upcoming KM3NeT in the Mediterranean, hunt for ghostly particles called neutrinos. These particles stream in from some of the most violent events in the cosmos: exploding stars, merging black holes, and the blazing cores of distant galaxies. Catching them in real time matters — but the detectors generate data at roughly 3,000 events per second, and next-generation experiments will push that rate eight to thirty times higher.
Current machine learning approaches run on powerful graphics cards, called GPUs — accurate, but hungry for electricity. Simpler processor-based methods, running on standard CPUs, use far less power but sacrifice precision. Scientists have been stuck choosing between fast-and-dumb and smart-but-power-starved.
A team from Harvard and the University of Washington has now found a third path: deploy machine learning directly inside the detector, on a chip that sips just two watts of power.
Key Insight: By combining a custom neural network architecture with aggressive quantization and deployment on a Google Edge TPU, the researchers achieved GPU-level reconstruction accuracy at CPU-level power consumption — a combination that wasn’t previously possible in resource-constrained detector environments.
How It Works
The heart of the approach is a carefully engineered neural network matched to unusual hardware. The Google Edge TPU is a microchip designed for machine learning inference at the network’s edge (think smart cameras or mobile devices), consuming only 2 watts for the chip itself and 3 watts for the full development board. Squeezing a physics reconstruction algorithm onto it requires rethinking the model from the ground up.
The team’s pipeline has three major stages:
-
Data preprocessing — Raw detector hits (photons arriving at optical modules) are transformed into a compact representation. The network receives time-series data from each optical module, encoding hit patterns in a way the Edge TPU’s constrained memory can handle.
-
Recursive network with residual convolutional embedding — The core is a recursive neural network, which applies the same transformation repeatedly to structured input — well-suited for the hierarchical geometry of thousands of optical modules. The inputs first pass through a residual convolutional embedding: a set of pattern-detecting filters that compress the full detector geometry into a compact summary the network can work with. Residual connections preserve information across that compression step.
-
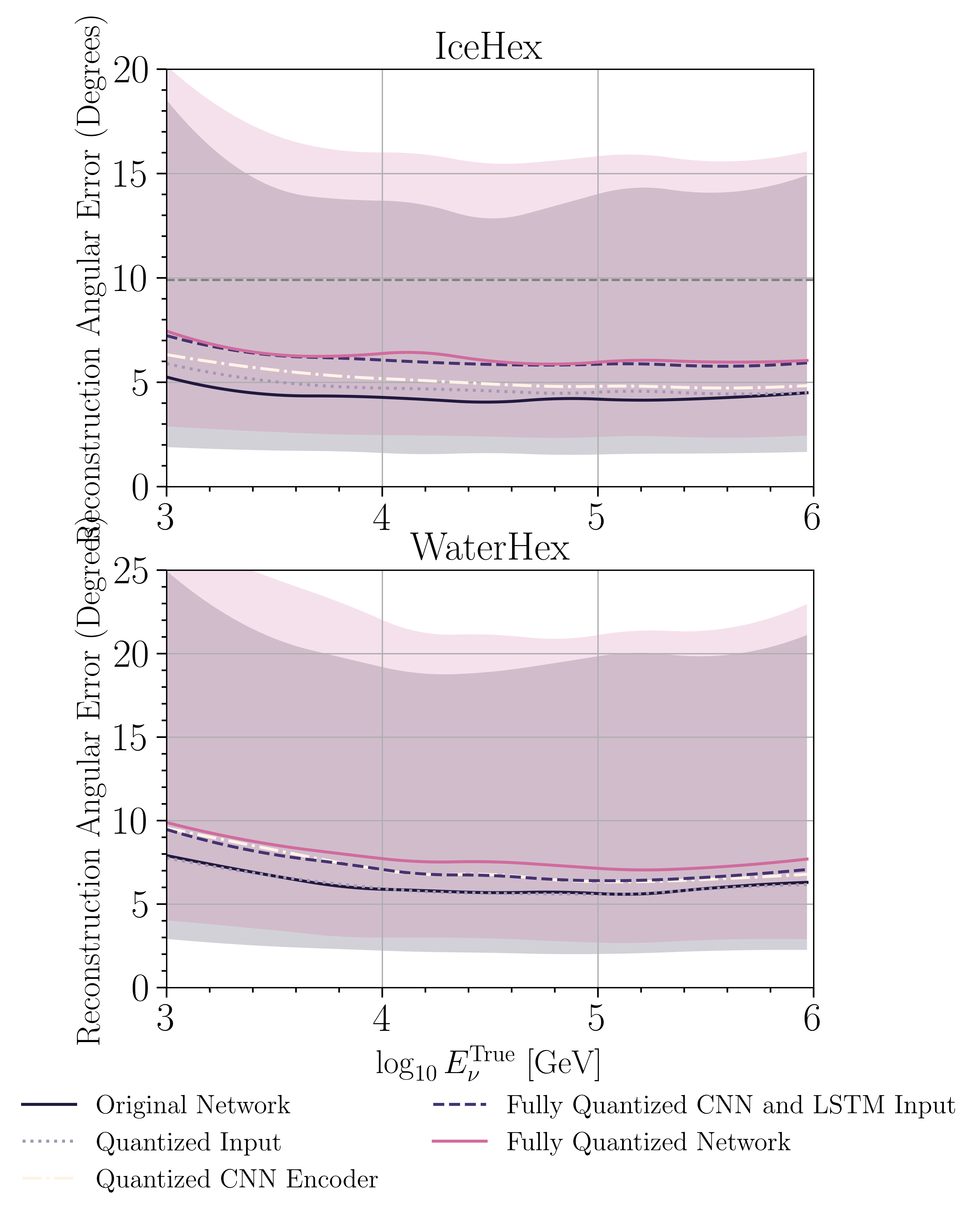
Quantization — Standard neural networks use 32-bit floating point numbers; the Edge TPU requires 8-bit integer quantization, shrinking numerical precision to a coarser grid, the only format the chip handles natively. Done naively, this destroys accuracy. The team adapted a fine-tuning procedure that retrains the network after quantization, recovering most of the lost precision.
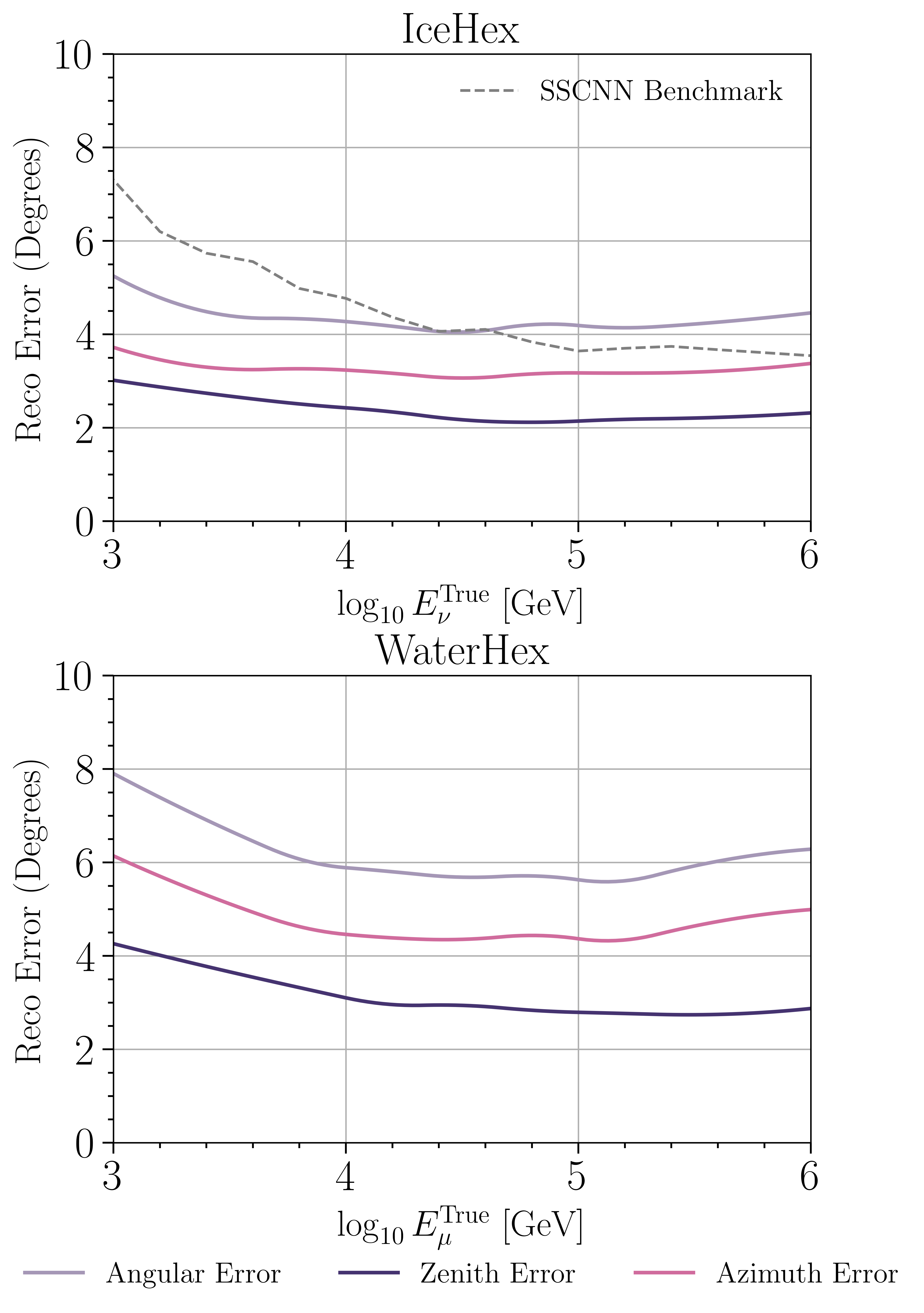
The two test detectors, WaterHex and IceHex, mimic realistic next-generation telescope geometries: 114 strings of 60 optical modules each (6,840 total), inspired by the KM3NeT layout but testing water and ice media separately.
Why It Matters
The numbers tell a clear story. The Edge TPU matches GPU-based reconstruction accuracy while consuming the same power as the simple CPU regression detectors currently used for real-time triggers. That’s not an incremental improvement — it collapses a tradeoff that has constrained the field for years.
The implications extend well beyond IceCube. Experiments like TAMBO in Peru and GRAND, a proposed radio-based detector, envision solar-powered remote stations where every watt is spoken for. TRIDENT in China will be thirty times larger than IceCube.
With power budgets measured in watts rather than kilowatts, in-detector intelligence has historically meant crude threshold cuts, not neural networks. This work opens a door to genuine real-time physics discrimination — separating signal neutrinos from background muons, flagging rare high-energy events for rapid follow-up alerts — without a power cable to the outside world.
The team frames this as a proof of concept, acknowledging that the current architecture is shaped by hardware constraints rather than optimized for peak reconstruction performance. Future iterations could explore newer edge AI chips, different quantization schemes, or hybrid designs where an edge processor handles first-level selection and passes only the most interesting events to more powerful off-site systems. There’s also a natural path toward deployment on actual IceCube hardware as part of the IceCube-Gen2 upgrade.
Neutrino astronomy is entering a data-rich era, and the algorithms that process those data need to live where the data are born. Pushing intelligence to the edge isn’t just an engineering convenience — for some of the most extreme physics experiments ever built, it may be the only option.
Bottom Line: Two watts is genuinely enough. This proof-of-concept shows that edge AI hardware can match GPU-level accuracy in neutrino reconstruction at a fraction of the power cost, unlocking real-time in-detector machine learning for experiments that were previously too power-constrained to benefit from it.
IAIFI Research Highlights
This work bridges deep learning model design with experimental particle physics constraints, translating GPU-era neural network methods into an architecture expressly shaped by the power and memory limits of remote detector hardware.
A full pipeline — custom recursive network with residual convolutional embedding, post-training quantization, and fine-tuning recovery — for deploying neural networks on 8-bit integer edge hardware without significant accuracy loss, a technique broadly applicable beyond physics.
Real-time in-detector ML reconstruction lets neutrino telescopes issue rapid alerts for rare astrophysical events and discriminate signal from background at the source, directly enhancing sensitivity to cosmic neutrino sources and new physics signatures.
Future directions include extending this framework to next-generation telescopes like IceCube-Gen2 and TRIDENT and exploring newer edge AI chips with higher throughput; the full paper is available at [arXiv:2311.04983](https://arxiv.org/abs/2311.04983).