
Unsupervised Decomposition and Recombination with Discriminator-Driven Diffusion Models
Authors
Archer Wang, Emile Anand, Yilun Du, Marin Soljačić
Abstract
Decomposing complex data into factorized representations can reveal reusable components and enable synthesizing new samples via component recombination. We investigate this in the context of diffusion-based models that learn factorized latent spaces without factor-level supervision. In images, factors can capture background, illumination, and object attributes; in robotic videos, they can capture reusable motion components. To improve both latent factor discovery and quality of compositional generation, we introduce an adversarial training signal via a discriminator trained to distinguish between single-source samples and those generated by recombining factors across sources. By optimizing the generator to fool this discriminator, we encourage physical and semantic consistency in the resulting recombinations. Our method outperforms implementations of prior baselines on CelebA-HQ, Virtual KITTI, CLEVR, and Falcor3D, achieving lower FID scores and better disentanglement as measured by MIG and MCC. Furthermore, we demonstrate a novel application to robotic video trajectories: by recombining learned action components, we generate diverse sequences that significantly increase state-space coverage for exploration on the LIBERO benchmark.
Concepts
The Big Picture
Imagine looking at a portrait photograph. Your brain effortlessly separates it into components: face, lighting, background. Nobody tells you where one ends and another begins. Teaching an AI to do the same, entirely without labels, is one of machine learning’s longest-standing puzzles: unsupervised disentanglement.
“Unsupervised” means the system receives no human-provided labels. “Disentanglement” means it must identify the hidden factors that shaped what it sees, like reconstructing a meal’s ingredients after you’ve already eaten it. Once identified, those factors can be recombined: swap the background from one photo onto another subject, or blend motion patterns from different robot demonstrations into novel trajectories.
A team led by researchers at MIT has now developed a method that makes this recombination far more coherent. The idea: add a “judge” network trained to catch implausible blends, then use its feedback to discipline a diffusion model, a generative AI that creates images by progressively refining noise into coherent pictures.
Key Insight: By training a discriminator to spot “fake” recombinations and optimizing the diffusion model to fool it, the system learns to produce blended outputs that are physically and semantically consistent, not just pixel-plausible, but actually believable.
How It Works
The foundation is a factorized latent diffusion model, a generative model that encodes each input into multiple separate hidden “slots,” each capturing a different aspect of the scene. (“Latent” means the model operates in a compressed internal representation, not on raw pixels.) Think of assigning separate notebooks to background, lighting, and subject identity; new images are generated by mixing notebooks from different sources.
The team builds on a prior framework called Decomp Diffusion, which showed promise for unsupervised slot learning. The problem: swapping components across images often looks uncanny. Lighting doesn’t match. Textures clash. The seams show.
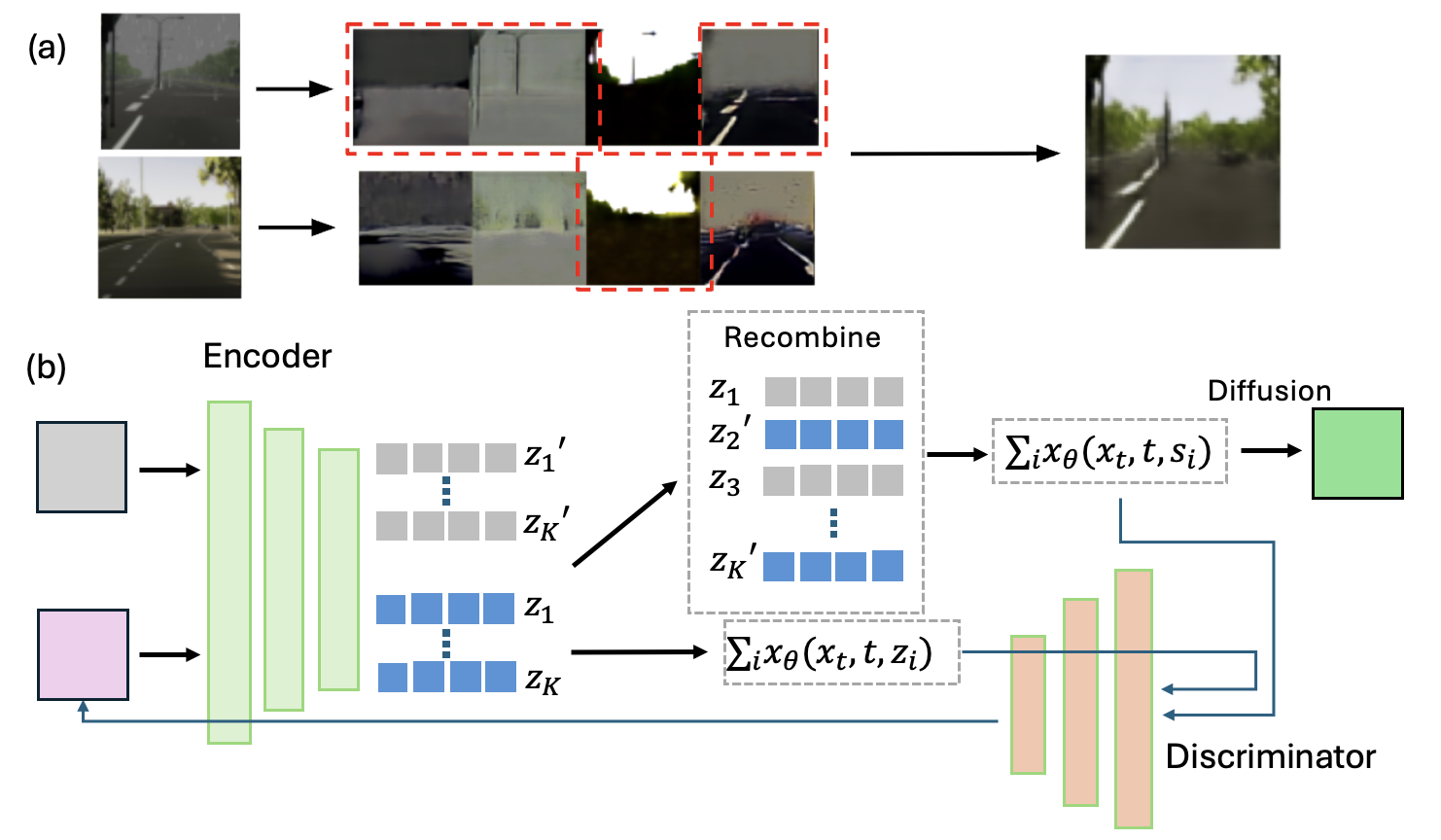
The fix is an adversarial training signal, a discriminator network trained to distinguish two kinds of outputs:
- Single-source samples: outputs generated entirely from one input’s latent factors
- Recombined samples: outputs generated by mixing factors from different sources
During training, the diffusion model is rewarded for fooling the discriminator, producing recombinations indistinguishable from single-source outputs. This creates a feedback loop: as the discriminator gets better at spotting inconsistencies, the generator is forced to produce more physically coherent blends.
The adversarial signal operates on intermediate denoising predictions, the model’s best guess about the final image at each step of the generation process, rather than waiting for the fully finished output. This allows training updates to flow efficiently without running the full denoising chain on every update.
Results across four standard benchmarks (CelebA-HQ for celebrity faces, Virtual KITTI for driving scenes, CLEVR for colored geometric objects, and Falcor3D for synthetic 3D scenes) consistently favor the new method. It achieves lower FID scores (Fréchet Inception Distance, measuring image quality and diversity) and better MIG (Mutual Information Gap) and MCC (Mean Correlation Coefficient) scores, which measure how cleanly learned factors correspond to the true underlying variables.
Why It Matters
The most surprising result comes not from images but from robots.
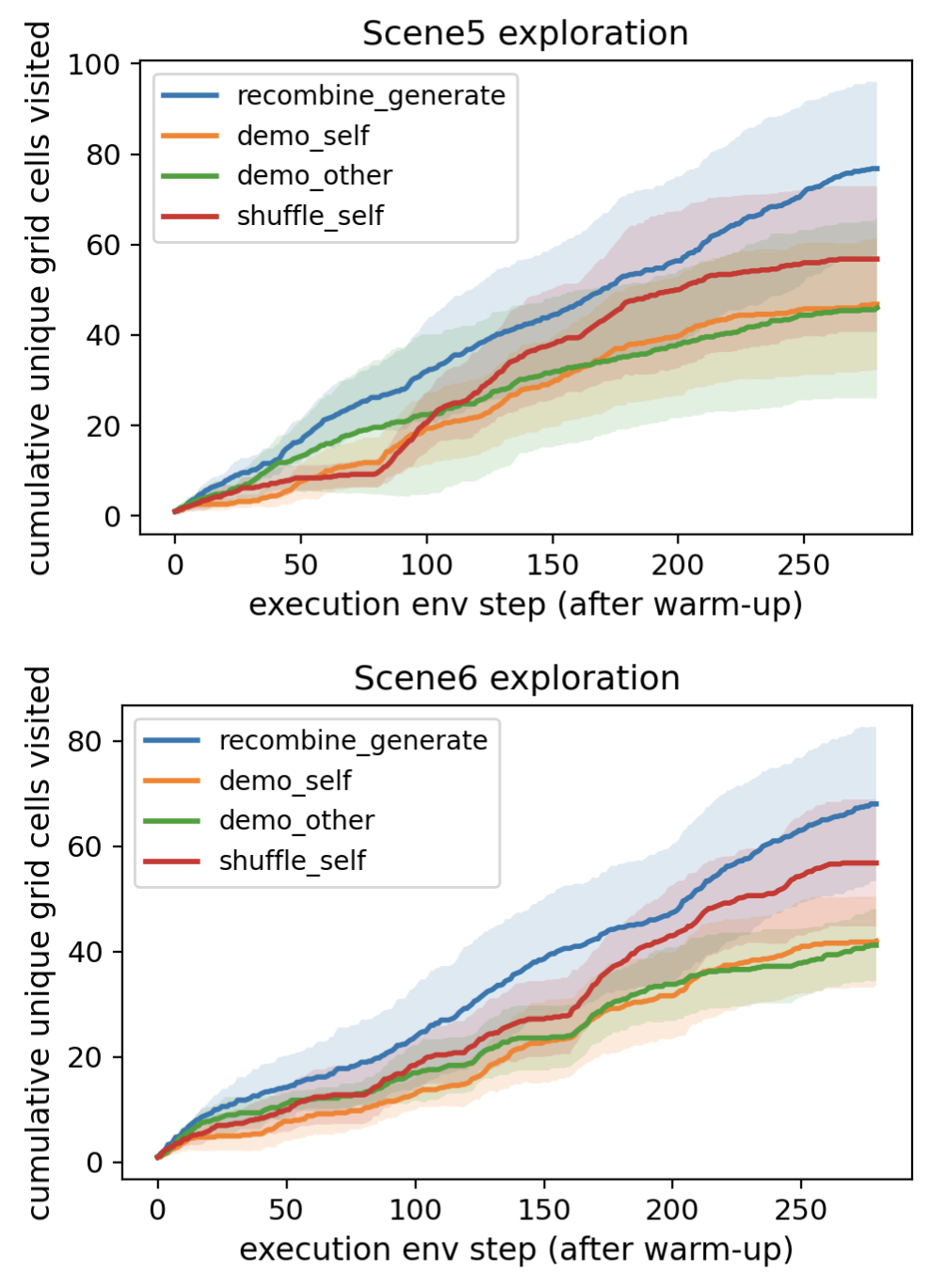
The team applied their method to video trajectories from the LIBERO benchmark, a standard testbed for robotic manipulation. Here, the “factors” aren’t visual attributes but action components: reusable motion patterns that recur across task demonstrations. By discovering these components without labeled examples and recombining them, the system generates entirely new robot trajectories absent from the training set.
These generated trajectories greatly increase state-space coverage, meaning the robot encounters a far wider variety of configurations during exploration. On LIBERO, this translates into more effective reinforcement learning: a policy guided by synthetic demonstrations explores much more of the environment than one relying on original data alone. Unsupervised factorization, it turns out, isn’t just an academic exercise in clean decomposition. It’s a practical tool for data augmentation in robotics, where real demonstration data is expensive and state coverage is everything.
There’s a deeper tension here between representation learning (building useful internal descriptions of data) and generative modeling (creating new data that looks real). The theoretical outlook has been discouraging: without additional structural constraints, fully unsupervised disentanglement is provably impossible. There are infinitely many equally valid ways to factor data, and nothing in the raw data alone selects the “right” one.
This paper doesn’t resolve that impossibility. But it offers something practical: a training signal that nudges the system toward representations that behave as if they’re disentangled, at least for the purposes of coherent recombination. The adversarial discriminator acts as a proxy for external feedback, the kind of signal that in a richer setting might come from human preferences, physical simulation, or task success. Can it be replaced by reward functions, physics engines, or human ratings? Can the approach scale to complex real-world video? These are productive questions, now grounded in a concrete working system.
Bottom Line: By pairing an adversarial discriminator with a factorized diffusion model, this work achieves cleaner disentanglement and more realistic compositional generation across images and robotic video, opening a concrete path toward using unsupervised factor discovery to boost exploration in robot learning.
IAIFI Research Highlights
This work connects representation learning theory, including ties to causal inference and independent component analysis, with modern generative modeling, showing how adversarial feedback can impose physical consistency on learned compositional structure.
The discriminator-driven diffusion framework advances the state of the art in unsupervised disentanglement, achieving better FID, MIG, and MCC scores than prior baselines across four benchmark datasets without requiring factor-level supervision.
The robotics application shows that unsupervised latent decomposition can generate physically realistic novel trajectories that substantially increase state-space coverage, offering a new approach to data augmentation for embodied AI systems.
Future directions include incorporating richer feedback signals such as physics simulators and human preferences, and scaling to complex real-world video domains. The preprint ([arXiv:2601.22057](https://arxiv.org/abs/2601.22057)) is available from MIT collaborators.