
Visual Dexterity: In-Hand Reorientation of Novel and Complex Object Shapes
Authors
Tao Chen, Megha Tippur, Siyang Wu, Vikash Kumar, Edward Adelson, Pulkit Agrawal
Abstract
In-hand object reorientation is necessary for performing many dexterous manipulation tasks, such as tool use in less structured environments that remain beyond the reach of current robots. Prior works built reorientation systems assuming one or many of the following: reorienting only specific objects with simple shapes, limited range of reorientation, slow or quasistatic manipulation, simulation-only results, the need for specialized and costly sensor suites, and other constraints which make the system infeasible for real-world deployment. We present a general object reorientation controller that does not make these assumptions. It uses readings from a single commodity depth camera to dynamically reorient complex and new object shapes by any rotation in real-time, with the median reorientation time being close to seven seconds. The controller is trained using reinforcement learning in simulation and evaluated in the real world on new object shapes not used for training, including the most challenging scenario of reorienting objects held in the air by a downward-facing hand that must counteract gravity during reorientation. Our hardware platform only uses open-source components that cost less than five thousand dollars. Although we demonstrate the ability to overcome assumptions in prior work, there is ample scope for improving absolute performance. For instance, the challenging duck-shaped object not used for training was dropped in 56 percent of the trials. When it was not dropped, our controller reoriented the object within 0.4 radians (23 degrees) 75 percent of the time. Videos are available at: https://taochenshh.github.io/projects/visual-dexterity.
Concepts
The Big Picture
Watch a surgeon flip a scalpel between their fingers mid-procedure, or a mechanic spin a ratchet into the right angle in a tight space. It looks effortless. Now ask a robot to do the same thing. You’re staring at one of the hardest unsolved problems in robotics.
In-hand object reorientation is exactly what it sounds like: holding something and spinning it to a new orientation without putting it down. A robot can’t use a screwdriver until it can flip it to align the tip with the screw. It can’t load a dishwasher, sort mail, or assist in surgery until it masters the casual dexterity humans develop as toddlers. Decades of research have attacked this problem, but nearly every prior system came with a long list of asterisks. Only works on simple shapes. Only in simulation. Only with expensive sensors. Only with the hand facing upward so gravity helps rather than hurts.
Researchers at MIT, Tsinghua University, and Meta AI have now built a controller that tears up that list. Using just a single off-the-shelf depth camera and hardware costing under $5,000, their system dynamically reorients complex, never-before-seen objects in real time, in any direction, even when the hand is pointed downward and fighting gravity the whole way.
Key Insight: A single cheap depth camera, whose measurements are processed as a 3D scatter of points (a “point cloud”), paired with a two-stage training pipeline, is enough to teach a robot hand dexterous reorientation that generalizes to entirely new object shapes.
How It Works
The core challenge splits into two problems: control (how do the fingers move?) and perception (what does the robot actually see?). Prior systems that cracked one usually stumbled on the other. This team’s approach solves them together through a teacher-student training paradigm.
The teacher is a reinforcement learning agent trained entirely in simulation. It receives ground truth data: exact object pose, finger positions, contact forces. It learns to reorient a diverse library of objects by any rotation. The student, by contrast, must work from a point cloud, a sparse 3D scatter of depth measurements from a real camera. Those measurements are riddled with occlusion (fingers constantly block the view), noise, and the sim-to-real gap, the persistent mismatch between how physics behaves in simulation versus the real world.
To handle point clouds at the speed manipulation demands, the team uses a sparse convolutional neural network, an architecture that computes only at occupied 3D locations and skips empty space. It runs at 12 Hz, fast enough for dynamic finger control.
Training the visual student was the biggest bottleneck. Naive rendering of photorealistic point clouds would have stretched a full training run past 20 days. The fix was a two-stage pipeline:
- Synthetic pretraining: Train the student on point clouds generated mathematically from object geometry, no rendering required.
- Rendered fine-tuning: Refine with photorealistic rendered point clouds to close the sim-to-real gap.
This cuts training time by about 5×, turning an impractical timeline into a workable one.
Then there’s the hand configuration. The robot grasps objects from above, fingers pointing down, meaning gravity constantly tries to pull the object free. Most prior work used upward-facing hands, where gravity pins the object helpfully into the palm. The downward configuration is dramatically harder but far more practical. A robot arm reaching across a table to grab a hammer doesn’t get to choose its hand orientation.
Why It Matters
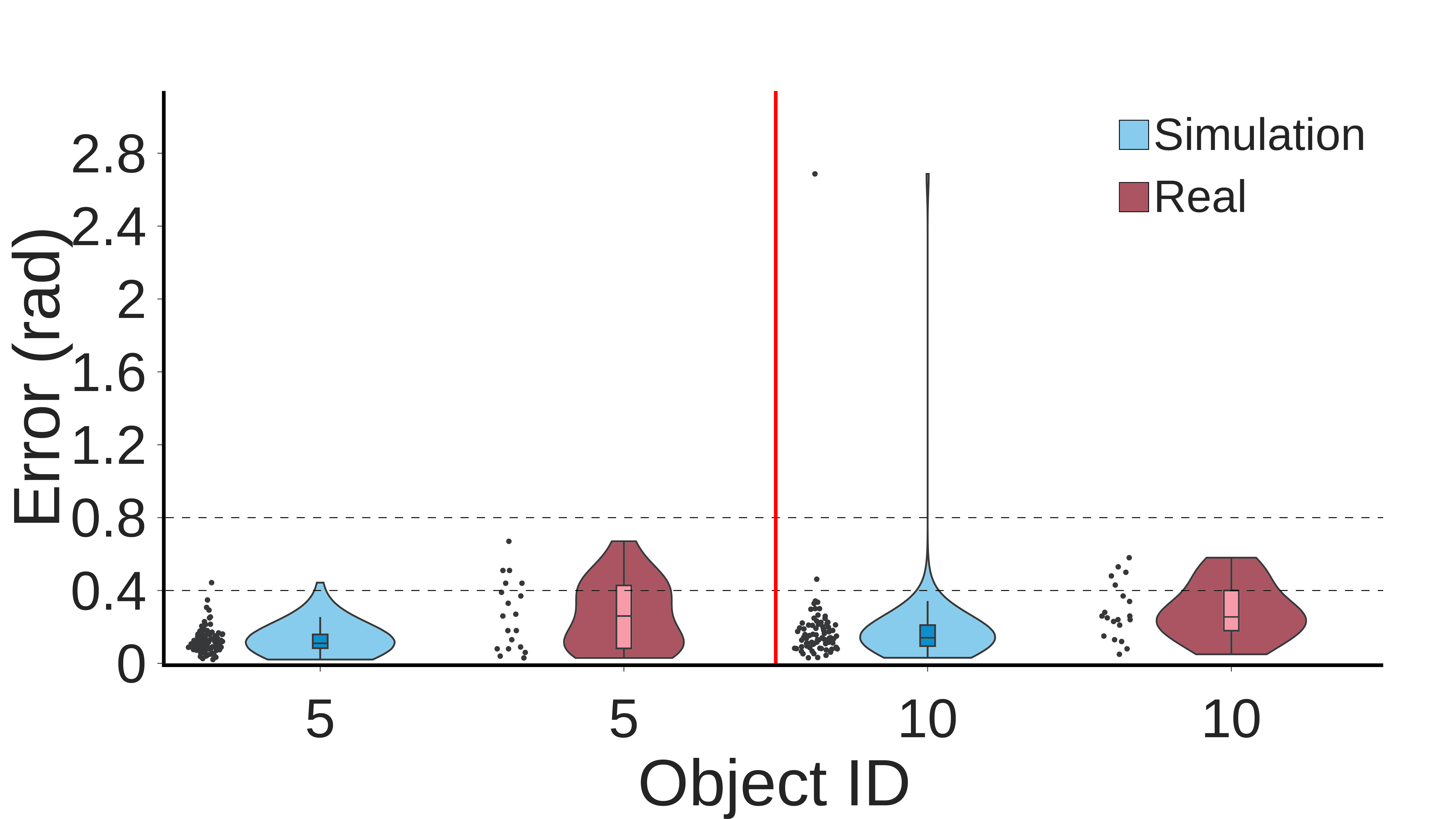
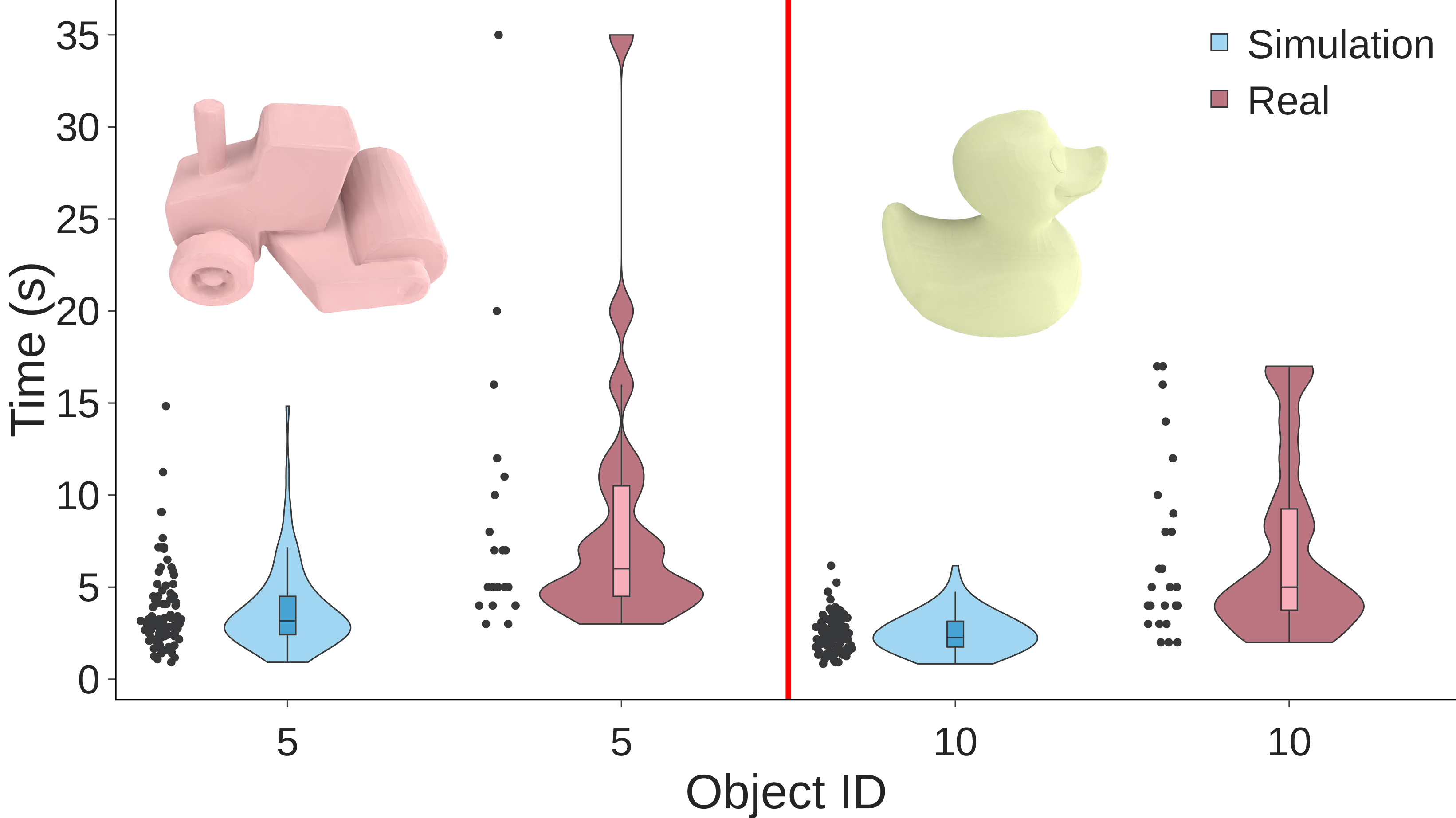
The benchmark results tell a story of real progress alongside honest remaining gaps.
On familiar objects, the system performs well, with a median reorientation time close to seven seconds. The hardest test was a duck-shaped object with irregular geometry the network had never seen during training. The robot dropped it 56% of the time. But when it held on, it hit the target orientation within 23 degrees in 75% of attempts. Imperfect, but a controller generalizing to a shape it has never touched is something new.
The bigger deal is the collapse of the “lab-only” barrier. Each constraint that prior systems required (specialized tactile sensors, multiple cameras, upward-facing hands, extremely slow motion, known object geometry) was a reason the technology couldn’t leave controlled environments. This system runs on open-source hardware under $5,000, uses a single commodity depth sensor, and handles objects it has never seen. Not plug-and-play for deployment yet, but the path from lab to world looks navigable for the first time.
Where does it go from here? Can the drop rate on novel objects come down? Can the approach scale to multi-step tool-use tasks, like picking up a screwdriver, reorienting it, and driving the screw? How does performance hold when the environment itself changes, not just the object shape? Each question points toward a generation of follow-on work.
Bottom Line: A single depth camera, the right neural architecture, and a cleverly staged simulation pipeline can unlock general-purpose in-hand reorientation, bringing dexterous robotic manipulation closer to real-world deployment.
IAIFI Research Highlights
This work sits at the intersection of deep reinforcement learning, 3D computer vision, and robotics control. Simulation-trained neural policies can now bridge to physical dexterity that previously required hand-engineered solutions or expensive sensor suites.
The two-stage teacher-student pipeline, with its synthetic-to-rendered point cloud training, offers a broadly applicable template for accelerating sim-to-real transfer in visual policy learning. The 5× training speedup over naive rendering makes the approach practical at scale.
By enabling manipulation of arbitrary object geometries in gravitationally challenging configurations, this research pushes AI systems toward engaging with the full complexity of the physical world rather than a curated subset.
Future work targets improved generalization to extreme object geometries, integration with downstream tool-use tasks, and further reduction of the sim-to-real gap. Full results are available at [arXiv:2211.11744](https://arxiv.org/abs/2211.11744).